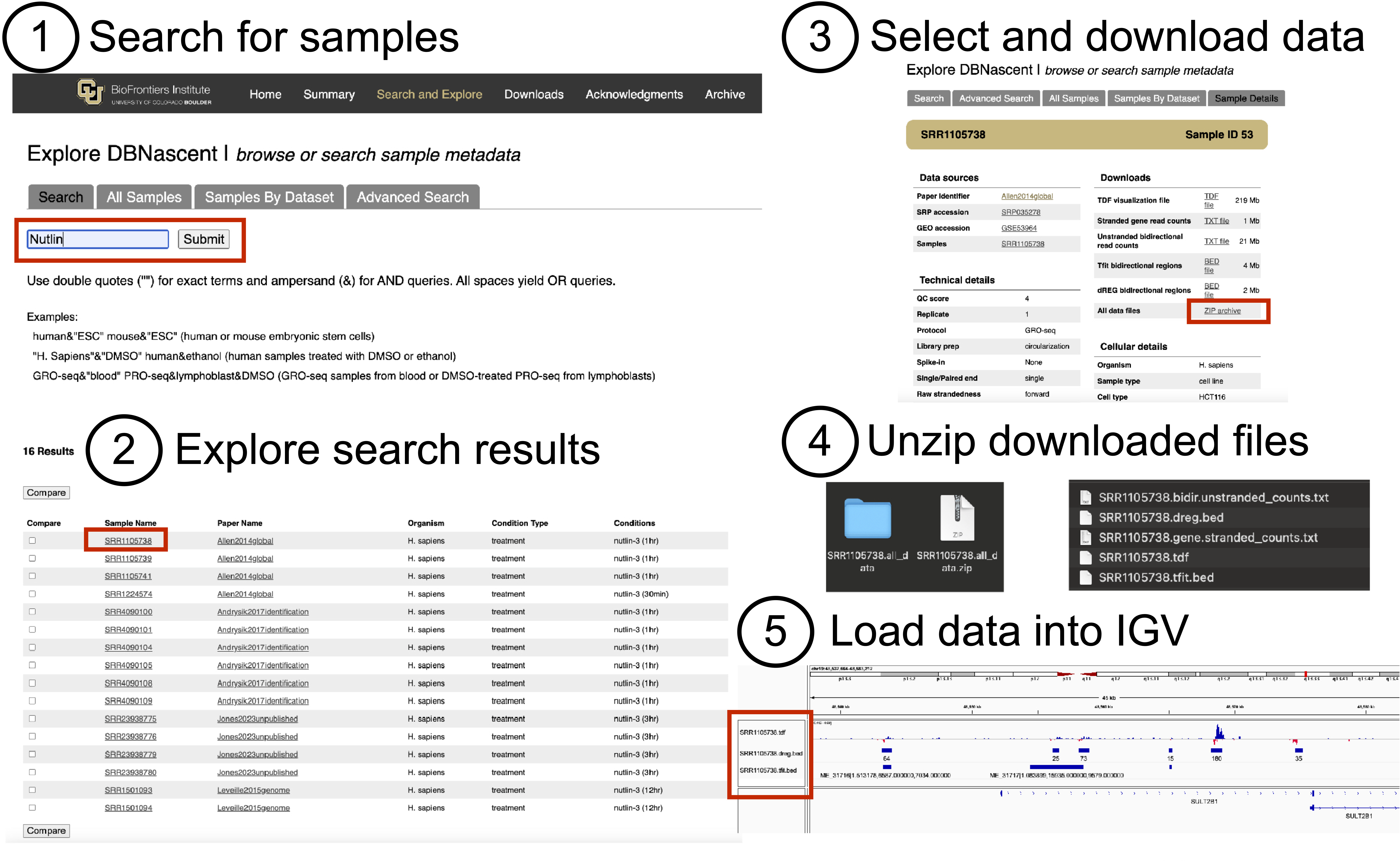
DBNascent is a large catalog of previously published sequencing data that is
primarily focused around nascent transcription assays. It currently contains
2888 individual samples derived from 288
individual experiments.
Metadata from publications and from the Gene Expression Omnibus and Short Read
Archive databases have been manually curated to describe many aspects of sample
types, conditions, and protocols. Samples have then been processed with a standardized
pipeline to mapped files, and further analyses have been conducted on human and mouse
samples to obtain read locations of bidirectional transcription and read counts
over several annotation sets.
Large data, particularly enhancer-gene linkages and other accumulated data are available
as Zenodo dataset 14519113.
Sample visualization files and processed data are available to download on our
Downloads page or within individual sample or
dataset pages (Explore the database).
General database usage: